Are Your Algorithms Ethical?

In 1989, Harvard Business School (“HBS”), seed ground for future CEOs, launched a required ethics class for the first time. I was managing editor of the student newspaper at the time, and wrote an editorial arguing that ethics should not be taught at HBS. I said that if you hadn’t developed a strong ethical code by the age of 25, it was probably too late to teach you.
I’ve since changed my mind. At a minimum, I think teaching ethics is at least worth a shot, and there’s a lot of life (and ethical decisions) left after 25. And the more experience I gain, the more I know that experiences can refine and modify our ethical values.
Here’s why every CEO should be concerned with ethics in their algorithms. Ethical choices influence perceived transparency and accountability. And that creates trust, the currency of our age. Further, a Harvard study released this week shows that people trust algorithms more than advice from other people.

Trust is even more crucial today, with frequent data breaches, CEOs called to account by the Senate, and new privacy regulations such as GDPR. Trust issues can cause consumers to leave a brand. For example, fully 79% say they would stop using a brand if it used their data without their knowledge.

Source: SAP/Hybris 2017 Consumer Insights Survey
Much has been made, and rightly so, of the potential for machine learning and artificial intelligence to help businesses sell more stuff through “lookalike” customer targeting, personalization, recommendation systems, and the like. But a few companies, like Toronto’s integrate.ai, are working on the complex issues of ensuring those machines have ethics, and thus trust, built right into their models.
“Machine learning systems are tools to optimize against a set of defined outcomes; it’s up to humans to define which outcomes to optimize for.”
To ensure that ethics are front and center in AI applications, integrate.ai recommends that corporations:
Understand the context in which machine learning is used, and consider applying machine learning to lower risk processes to start. Consider keeping a “human in the loop” to help make a decision or provide feedback to help train the system.
Ask customers what their perspective is as to appropriate uses of their data. Direct surveys and social listening systems such as Sprout Social and Spredfast can be very useful tools in this regard.
Avoid unintentional bias associated with correlation with other, seemingly benign, data.
Consider abstracting data so that individuals are not personally identifiable.
Institute data governance processes to ensure third party data are clean, groups such as minorities are appropriately represented in the data, and security controls are applied to all data, at rest and in transit.
Ensure there is an audit trail to enhance “explainability” of a decision. This involves governance decisions about things like length of data storage as machine learning models change.
An example of applying machine learning to lower risk applications first comes from Kanetix, the insurance aggregator. They use the integrate.ai platform to predict which customers are likely to respond to an incentive offer. Because incentives can be costly, It offers deals only to those prospects most likely to “bite” on the incentive. Determining whether to offer an incentive is a lower-risk process on which to apply machine learning, compared to say, figuring out who qualifies or doesn’t for a life insurance policy.
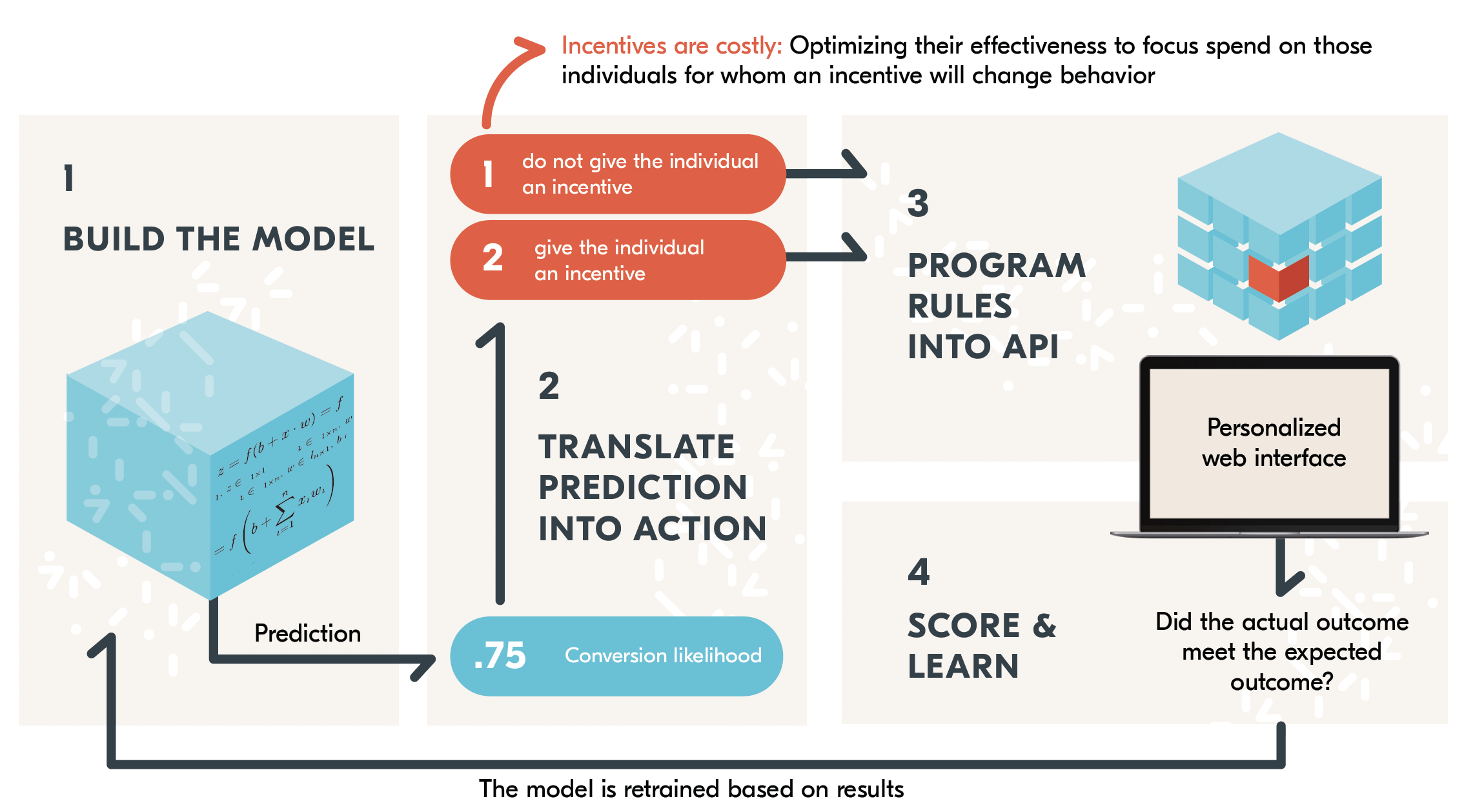
Machine learning models help Kanetix decide which prospects are offered incentives to purchase. Source: integrate.ai
Unintentional bias can be inadvertently introduced to these models, either in the dataset selected or the labels used. As an example, postal code data can be a proxy for ethnic background. If your model uses location data in decision-making, you could inadvertently treat different ethnic groups unfairly. Machine learning systems will continue to propagate biases, and enhance them via feedback loops, if bias is not detected and corrected.
Techniques such as differential privacy, used by Google, Facebook, and Uber, can be used to modify data such that statistical features required for a model are left intact, but it is not possible to tell the difference between a result that contains and does not contain an individual. Other techniques include cryptographic hashing and masking (pseudonyms). It is important to establish a policy about partner use of company data, because if each party’s dataset contains the same individuals, the data could contain keys or “clues” to unlock the other’s “masked” data.
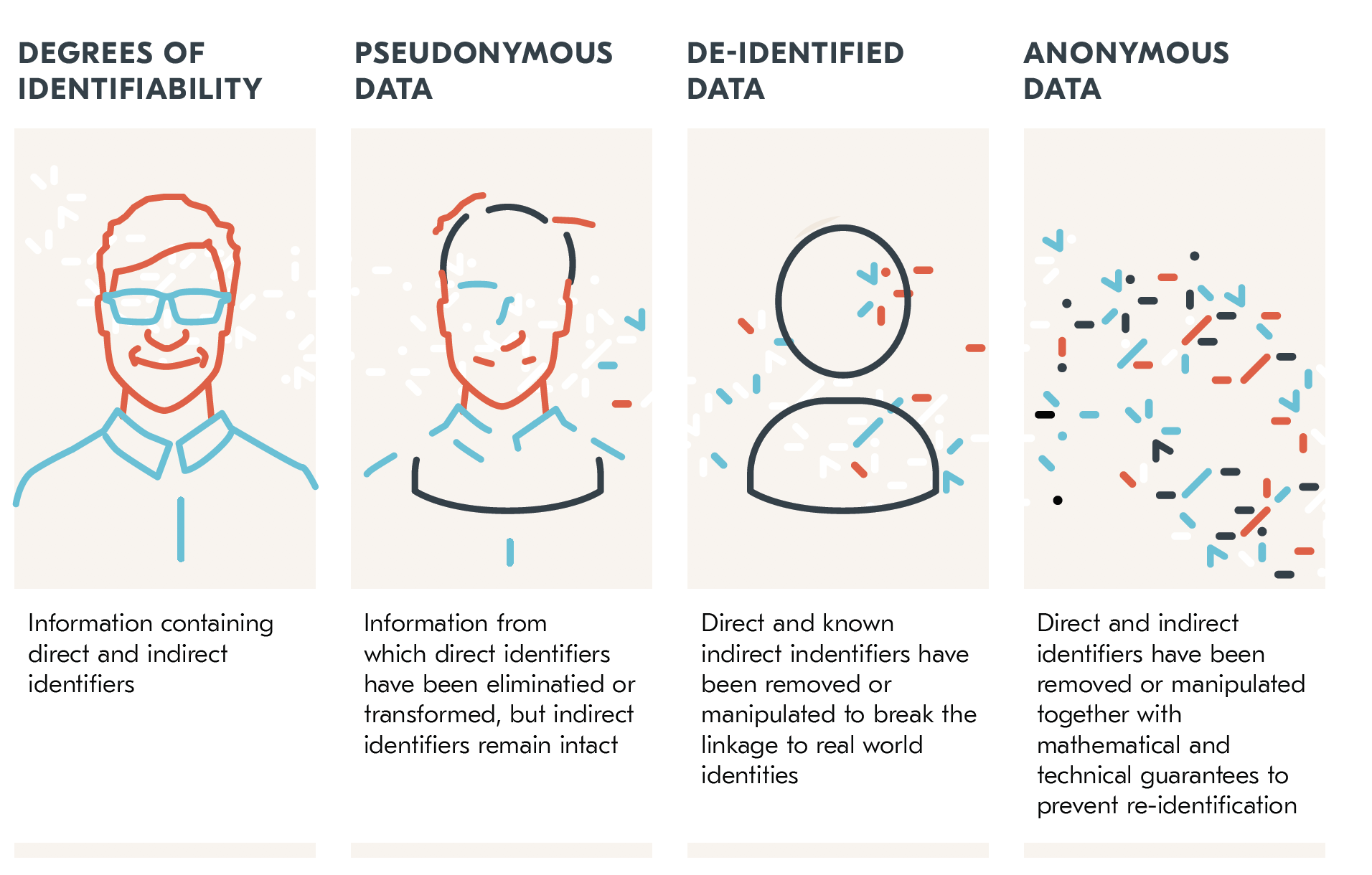
Source: integrate.ai
Finally, thoughtful governance policies and systems are crucial to ensuring ongoing ethical collection, treatment, and disposition of data. Best practices include seeking ongoing input from cross-functional participants, ensuring incentives and KPIs support ethical behaviour, brand voice and tone guidelines to ensure a consistent approach to handling customer situations, and regular senior management review.
“At Scotiabank, we don’t see data governance as just a compliance exercise or a way to manage risk. For us, it’s a source of competitive advantage and a way to deliver meaningful value to our customers, while maintaining their trust.”
Make no mistake, many customers in the 21st century will make purchase decisions based on who, or what, they can trust. Smart businesses will make sure their algorithms, as well as their people, take that into account.